The Architect in the Graph
How the Bottleneck in Enterprise Software Is Finally Starting to Break
In 1975, Fred Brooks published The Mythical Man-Month. Brooks had run the development of OS/360, IBM’s flagship operating system and the largest software project the world had yet attempted. It was late, over budget, and difficult in ways that surprised the people running it. Brooks wrote the book to name the patterns that turn large software projects into career-ending disasters. The book is fifty-one years old, still in print, still assigned to graduate students — because the problems he described in 1975 have not been solved.
Every generation has tried. Structured methods in the late 1970s. CASE tools in the 1980s. Object-oriented design and UML in the 1990s. The agile manifesto in 2001. DevOps in the 2000s. Low-code platforms in the 2010s. Each made real progress. None solved the problem Brooks named: complex software requires architectural rigor — a unified vision of what is being built, why, and how its pieces fit — and that rigor has always required a small number of people with deep expertise to hold the whole picture in their heads.
The architects existed. The architectural understanding existed. What never existed was a way to make that understanding available to everyone else on the team.
Until now.
Table of contents
Why this generation is different
When generative AI shows up in a domain, the safe prediction is that it will do what every earlier generation of tools did: help the experts, automate the routine, and leave the hard parts to humans. This time, the safe prediction may be wrong.
The breakthrough is not that AI can generate code. It is not that knowledge graphs are now feasible at enterprise scale. Both are real. You can see the market converging on graph-backed context — Microsoft’s GraphRAG, Salesforce’s Waii, the Agentforce agent-graph framing, Elements.cloud’s Operational Graph, MeshMesh’s context model — and that convergence is itself a signal.
The deeper breakthrough is that architectural understanding is starting to become portable. The kind of model of the enterprise that used to live only in the heads of senior architects can now travel with the work — though portable does not mean automatic or correct by default. The graph still has to be modeled, governed, versioned, and audited. What has shifted is that the cost of doing that work is falling fast enough for the graph to become shared infrastructure rather than a one-off architecture project.
In Virtual Employee Economics, I call this cognitive commoditization — AI lowering the cost of applying a scarce cognitive skill repeatedly across an organization. Architectural reasoning is the next skill entering that transition.
What makes it possible is that the substrate has finally arrived. You cannot store the kind of knowledge an architect carries in their head as a list of rules, a set of templates, or a stack of documentation. You need a structure that can hold relationships — how one part of a system depends on another, how one business rule constrains a downstream decision, how one authorization flows from one role to another.
That structure has a name. It is called a knowledge graph. And it has just become accessible to organizations that previously could not have built one.
What is a knowledge graph?
A knowledge graph is a way of representing information by writing down two kinds of things. The first is the entities — the people, the records, the systems, the rules. These are called nodes. The second is the connections between them — who reports to whom, which record belongs to which account, which rule applies to which transaction. These are called edges.
If you have worked with a Salesforce org, you have already worked with something graph-like. A foreign key in a SQL table, the field on a Contact that points to its Account, is doing the same job as an edge. The Contact is a node. The Account is a node. The lookup is the edge. The graph is what you get when you stop thinking about each table separately and start thinking about all the relationships at once.
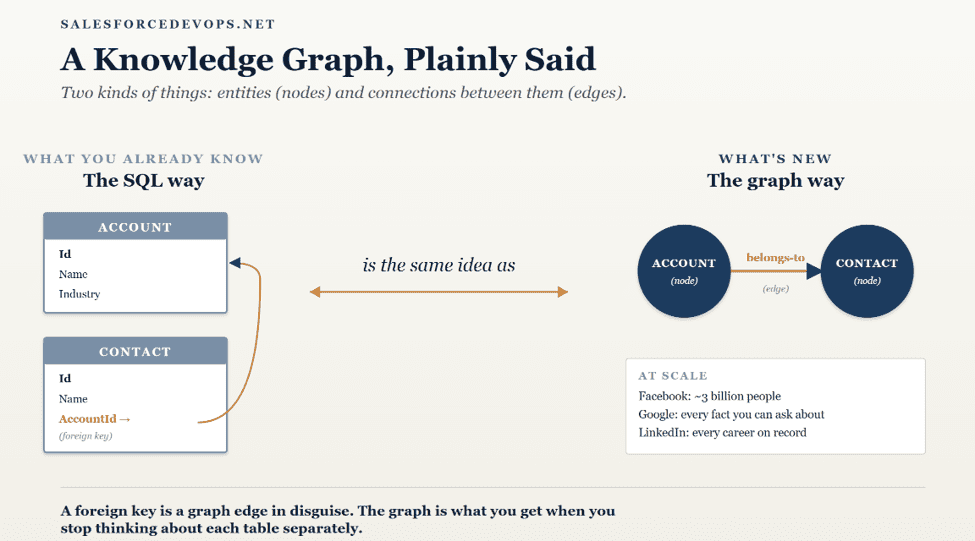
A note on terminology. “Knowledge graph” is being used in the market today to mean several different things: graph databases, semantic layers, metadata catalogs, GraphRAG retrieval architectures, and operational ontologies. I am using it in the operational sense — a structured, queryable representation of an organization’s intent, data, and relationships, governed and kept current as living infrastructure.
Until recently, building a graph like that — one that captured the relationships among intent, data, processes, policies, and systems — required exactly the kind of senior architect Brooks’s book is about. You had to know what to put in, what to leave out, which relationships mattered, and how to maintain the graph as the business changed. Most enterprises that tried this in the 2000s and 2010s gave up because the maintenance cost exceeded the value.
What has changed is that generative AI can now do enough of the first-draft and maintenance work to make the graph economically plausible. It can read documentation, requirements, transcripts, and system metadata to produce a first draft. It can keep the graph current as new information arrives. It can answer questions about the graph in plain English. It can flag where the graph is incomplete. Not because the graph is easy — because the cognitive work of building it is becoming commoditized.
What this changes for selling and development teams
If architectural understanding lives in the graph, and the graph can be queried by anyone with permission, then the question of who can build architecturally rigorous software changes. The first place this changes behavior is not coding. It is commitment-making.
Until now, a salesperson scoping an Agentforce deployment had to either bring an architect into the conversation or commit to scope choices they did not have the expertise to evaluate. With the architectural knowledge in the graph, the salesperson scopes the deployment with the graph as their partner — describing what the customer needs in their own words, and getting back a plain answer: this fits, this does not, this requires a decision you should escalate. The graph is doing the architectural reasoning, not the salesperson.
Make it concrete. A customer asks for an Agentforce deployment that will recommend renewal discounts, update opportunity fields, trigger an approval, and notify the customer success manager. In the old project model, the seller scopes the use case in a Friday meeting and commits to delivery in six weeks. The architect later discovers the discount logic conflicts with an approval policy on regulated accounts. Three sprints in, the developer finds that a field update fires a Flow writing to a downstream object the seller did not know existed. Compliance asks, the day before launch, why the agent has been authorized to touch a regulated field on segment-B customers. The project slips two quarters and ships with reduced scope.
In the graph model, the relationships exist as connected nodes before the seller makes the promise. The opportunity field, the approval policy, the Flow, the downstream object, the permission set, the Data 360 mapping, the regulated-field policy — all of them are addressable and queryable. The seller scopes with the graph open. The graph says: allowed for segment A, blocked for segment B, requires architect review because this flow writes to a regulated object. The seller commits to a deployment the organization can actually deliver. The agent, when it eventually runs, is not answering from documentation. It is operating against the architecture itself.
The same shift happens for developers. The graph tells them which fields they are allowed to touch, which downstream systems will be affected, and which business rules apply. The architectural knowledge is becoming a shared resource. The expertise that used to be a bottleneck has become a substrate.
What the industry is building toward
Look across the market and the shape is forming, though no two efforts are approaching it the same way. The graph database vendors — Neo4j, Stardog, the RDF triplestore market — are not the story. They are infrastructure. The story is the layer above them: the people designing the schemas, the ontologies, the methodology, and the AI tooling that capture why an IT estate looks the way it does.
Palantir Foundry is the most mature expression of the idea. Foundry’s Ontology is not a database; it is a methodology with a product attached. It binds an organization’s integrated datasets to real-world objects — equipment, customers, orders, financial transactions — along with the action types and business logic that govern how those objects can change. Palantir describes it as the operational layer for the organization. Foundry is what an enterprise knowledge base looks like when a vendor has been refining the practice for the better part of a decade with defense and intelligence customers as patrons.
Inside the Salesforce ecosystem, the same pattern is appearing. Salesforce’s Data 360 and Agentforce roadmap, sharpened by the Waii acquisition, is moving toward a substrate that agents reason against rather than retrieve from. Elements.cloud has been working this problem longer than most, building an Operational Graph that captures not only what is in a Salesforce org but why it is there. MeshMesh is building a context model aimed at customers who need to reason across Salesforce, ServiceNow, and SAP at once. The traditional enterprise-architecture vendors are pivoting hard into the same space.
The implementations differ. The shape is converging.
That shape is a living knowledge graph that holds an organization’s architectural understanding — its intent, data, policies, processes, systems, and the relationships among them — rich enough to act as a partner to anyone who needs to operate within those boundaries. The graph is not a documentation tool. It is not a wiki. It is not a SharePoint folder. It is a working representation of how the organization fits together, kept current by AI doing the maintenance work humans previously did badly or not at all. This is the substrate the previous fifty years of tooling kept reaching for and could not hold.
Every previous generation promised that complexity would yield to method. Every previous generation delivered less than promised. This generation is different because the constraint that defeated its predecessors — the cognitive cost of building and maintaining the architectural representation, and especially the why behind it — has begun to fall.
What the graph cannot do
For the graph to be worth trusting, it has to be governed like production infrastructure. Edges need provenance — where each relationship came from and who confirmed it. Recommendations need confidence levels. Permissions need to determine who can query and modify which parts of the graph. Changes to load-bearing relationships need versioning, review, and rollback. The graph is not useful because it is comprehensive. It is useful because people can trust the parts of it that matter.
A confident essay about a new substrate also owes its readers an honest account of what it cannot do. The graph is not magic, and architects who lived through the previous four generations of tooling will be ready with objections. They are right to have them. Five failure modes deserve to be named.
- Edges can be wrong. The graph claims a relationship that does not exist, or omits one that does. Wrong edges produce confidently wrong reasoning, which fails silently rather than visibly.
- Documentation goes stale. Processes change, fields are deprecated, policies are revised. A graph that no one maintains starts to lie. AI maintenance helps but does not eliminate the problem.
- Business intent is often undocumented. The reason a customer segment is treated differently lives in the head of the VP who set the policy three years ago. The graph cannot extract what was never written down.
- AI hallucinates relationships. Generative models building the graph will sometimes propose plausible edges that correspond to nothing real. Retrieval grounding, schema constraints, and human review help. Graphs that accept AI-proposed edges without verification will accumulate errors faster than maintenance can correct them.
A graph can preserve bad architecture as easily as good architecture. If the underlying systems are themselves incoherent, the graph that represents them faithfully will be incoherent too. The graph is a mirror, not a corrective. It makes a tangled architecture navigable, not untangled.
The right way to read these failure modes is that the graph does not eliminate architects. It changes their leverage. Architects become the people who define the ontology, validate the load-bearing relationships, set the confidence thresholds at which graph-derived recommendations are safe to automate, and decide which kinds of business intent are explicit enough to be modeled. The architect’s job moves from holding the whole picture in their head to curating the substrate that holds it for everyone. That is a more leveraged job, not a smaller one.
What you should be thinking about now
If this analysis is right, the most important question for anyone running an IT organization in 2026 is not what tools to evaluate. It is whether your team understands why they do what they do.
AI is going to keep collapsing the routine work in IT departments. The configuration tasks. The integration glue. The reporting builds. The status updates. The first-pass triage. The work that has been the daily texture of an IT career for thirty years is being automated first, because it is what AI is best at and what organizations are most willing to pay to remove.
What does not get automated, and what becomes more valuable as the routine collapses, is the knowledge of why the organization does what it does. Why this approval flow exists in this shape. Why this customer segment is treated differently. The why-knowledge keeps an organization coherent across years of change. It has historically lived only in the heads of long tenured employees and been lost when they retire or move on. The IT leaders who succeed over the next five years will be its custodians.
When AI collapses the routine work in your department, the people who understand why things are done the way they are will deploy these knowledge partners most effectively. The why-knowledge is becoming the moat.
Vernon Keenan is the publisher of SalesforceDevops.net and CEO of Keenan Vision LLC. He advises Salesforce executive leadership on AI strategy and competitive positioning, partners with UC Berkeley Haas on research into Virtual Employee Economics and originated the Builder Gap and Quiet Erosion analytical frameworks shaping industry conversation about enterprise AI deployment.