
Retrieval-Augmentation Generation Ushers in a New Generation of Advanced AI Capabilities
Happy New Year everybody from SalesforceDevops.net! I’m pleased to share an interesting academic study I found to be especially timely. “Retrieval-Augmented Generation for Large Language Models: A Survey,” authored by a team led by Yunfan Gao from Tongji University, Fudan University, and others, offers a comprehensive review of the development and implementation of Retrieval-Augmented Generation (RAG) in Large Language Models (LLMs).
Large language models (LLMs) like ChatGPT stunned the world by showcasing remarkable language mastery and comprehension abilities. However, as the initial euphoria settles, practitioners have identified crucial limitations in purely parameterized foundation models. LLMs struggle with keeping knowledge updated, tend to hallucinate facts, lack interpretability, and fail to handle specialized domains. An emerging solution gaining rapid traction is combining LLMs with external knowledge retrieval in a paradigm called Retrieval-Augmented Generation (RAG).
This survey provides a timely and structured analysis of the components, optimizations, and future potential of retrieval-augmented models enabling transformative AI capabilities. This is evidenced by recent adoption by technology giants like Microsoft, AWS, and Salesforce into their product portfolios, indicating the pivot of RAG from research into enterprise readiness, aiming to unlock even more capable AI systems.
Table of contents
The Transformative Promise of RAG
RAG aims to synergize the complementary strengths of parameterized and non-parameterized knowledge. The parameterized knowledge contained within the weights of large neural network-based models forms their core competency. However, the non-parameterized knowledge in external corpora can provide frequently updated, trustworthy information to handle specialized domains. RAG provides the best of both worlds – innate broad capabilities from pre-trained LLMs enhanced via context from reliable information retrieval.
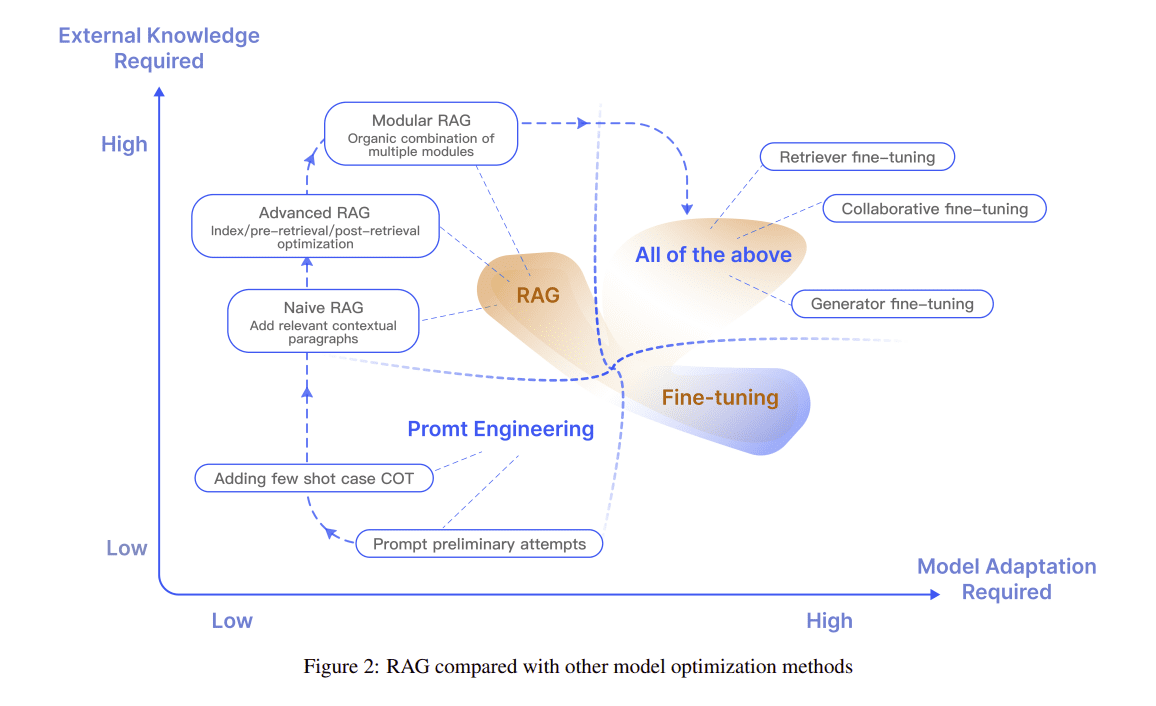
Early RAG techniques focused primarily on end-to-end pipeline optimization of retrievers and generators. However, the survey notes RAG is now transitioning to a more modular paradigm. One where retrievers and generators are separate components that can be independently optimized. This facilitates customization of knowledge sources, retrieval techniques, and choice of LLMs themselves. Modular RAG also enables easier upgrades as better foundation models emerge. Overall, it provides greater control to build RAG systems tailored to specific use cases.
Key Components That Power RAG Models
The authors organize analysis of RAG methods into three core components that enable the supplementation of external knowledge to enhance LLM-based generation:
Knowledge Retrieval
The retrieval module focuses on acquiring accurate vector representations of text segments through semantic embedding. Key capabilities include:
- Corpus Processing: Techniques like metadata filtering and graph representation of structured facts that facilitate precise mapping of concepts.
- Embedding Optimization: Supervised fine-tuning of semantic models using domain data and LLM feedback signals to tighten query-document alignment.
- Re-ranking: Post-retrieval steps like selective compression and re-ordering to provide generator with most relevant information.
Knowledge Augmentation
This module examines the sources for supplemental knowledge and how to effectively integrate it with LLM contexts:
- Data Sources: Unstructured corpora, knowledge graphs and even LLM-generated content. Each format poses distinct augmentation challenges.
- Multi-step Retrieval: Iterative and adaptive techniques overcome limitations of single-pass retrieval like redundancy and inadequate context.
- Seamless Integration: Methods like contrastive learning, perceived as promising directions to fuse retrieved knowledge within generators.
Text Generation
Generating coherent, relevant output using contexts from input text and retrieved documents requires adaptable generator models:
- Input Consolidation: Compress unimportant retrieved details and emphasize most pertinent information for generator.
- Model Optimization: Fine-tuning via domain-specific data and cross-attention with language model output signals to enhance assimilation of external knowledge.
The Evolution of RAG Frameworks
The authors categorize the development of RAG systems into three paradigms reflecting increasing sophistication:
Naive RAG
Involves standard pipeline of indexing corpora, embedding-based semantic retrieval using input query and text generation by conditioning pre-trained LLM on documents from previous step.
Advanced RAG
Enhances Naive RAG components like applying metadata filters during indexing for efficient search and supervised in-domain fine-tuning of embeddings for tighter query-document alignment.
Modular RAG
Emerging as the most flexible architecture. Allows swappable modules like substituting retrievers with LLM-based generators or adding steps like post-retrieval validation. Overall, facilitates extensive customization.
Of these, Modular RAG shows most promise to balance innovations in LLMs themselves and retrieval augmentations to overcome their weaknesses.
Assessments and Future Outlook
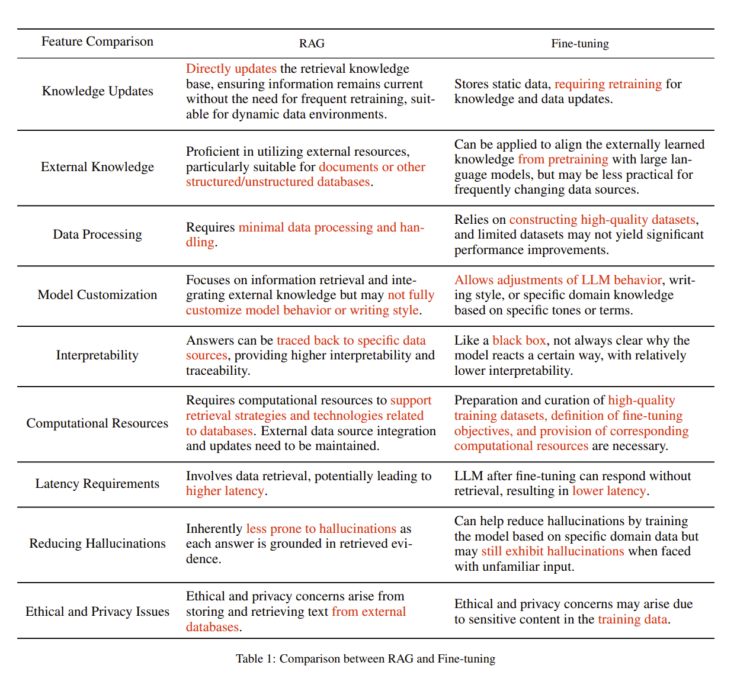
Compared to other LLM optimization techniques like fine-tuning, the authors highlight five key advantages of retrieval-augmented models:
- Improves accuracy and trustworthiness by grounding responses in retrieved evidence.
- Enables easy updates by modifying documents instead of retraining models.
- Provides transparency through cited sources.
- Allows domain customization via relevant textual corpora.
- Technically and economically more scalable than full model retraining.
Nevertheless, RAG faces ongoing challenges like effectively handling long contexts, guarding against noisy retrievals undermining generation quality and finding the right synergy between retrieval and fine-tuning.
Future promising directions involve refinements within components like handling unlimited context sizes to innovations across paradigms like applying RAG to multimodal inputs beyond just text. Maturing the RAG technology stack for widespread real-world deployment remains an overarching imperative.
Retrieval-Augmented Generation: Out Of The Lab
This survey paper presents a structured blueprint for developing retrieval-augmented language models (Gao et al., 2023). RAG strikes an appealing balance between pre-trained LLM capabilities and continually updated world knowledge.
Seeing this potential, major cloud providers like Salesforce, Microsoft and AWS are committing engineering resources to leverage RAG within popular developer tools, search, and content enrichment offerings. Rapid innovations in neural information retrieval to efficiently extract relevant contexts coupled with adaptable generator models to seamlessly utilize these contexts offer an exciting path to overcoming limitations of current AI systems.
With modular and customizable architectures, RAG deployments promise to usher in a new generation of substantially more capable LLMs in the future.
Citation: Gao, Yunfan, et al. “Retrieval-Augmented Generation for Large Language Models: A Survey.” arXiv preprint arXiv:2312.10997 (2023).





